
SEO Crawler początek
Podstawą każdego porządnego audytu strony jest poznanie struktury danego serwisu. Na tej samej zasadzie jak crawlery w narzędziach pozycjonerskich działają tez wyszukiwarki internetowe które crawluja nasz serwis, sprawdzają parametry podstron i indeksuja je w swoich zasobach.
Spis treści
Do crawlowania/audytowania stron dostępnych jest wiele narzędzi takich jak najpopularniejszy Screaming Frog czy zaawansowany kombajn taki jak pakiet SEO PowerSuite. Są to genialne narzędzia jednak maja swoje ograniczenia:
- Funkcjonalności które dostępne są w tych programach zostały zdefinowane przez jakiego magika czytaj twórce oprogramowania. Ogólnie nie byłoby to wada gdyby nie to ze jeżeli potrzebuje się specyficznego rozwiązania dla danej strony to jesteśmy zdani na to co wymyślił twórca programu. Drugą kwestia jest także to że czy audyt przeprowadza znany SEO celebryta czy junior seo widza te same dane wiec wnioski z dwóch audytów mogą być takie same, a zostanie przeoczony ważny element którego nie uwzględnił w sofcie twórca Screaming Frog.
- Dla mnie największa wada – są to aplikacje natywne których nijak nie da się skalować, nie mogą monitorować podstron w trybie ciągłym i przy 100 domenach do pozycjonowania jest to po prostu niewygodne i mało efektywne narzędzie.
- Nie można zautomatyzować procesu w 100%. Trzeba crawlowanie odpalać itp a ja potrzebuje coś co sprawdza parametry wszystkich witryn raz na godzinę i crawluje całą domenę raz w miesiącu bez mojej ingerencji, wysyła powiadomienia i automatyczne audyty.
Ponieważ zarówno serwerami jak i programowaniem zajmuje się już dobrych parę lat zacząłem pisać swoja własną wersje crawlera, Dzisiaj śmiało mogę Wam zaprezentować funkcjonalności SEO Crawlera / Auditora i SpiderBota w wersjach 2,0
Sam crawler składa się ze skryptu PHP połączonego z sqlite na nodzie który crawluje oraz serwerów bazodanowych opartych na mongoDB i MySQL. Oczywiście do działania systemu wystarczy jedna linuksowa maszyna jednak wtedy zyskujemy trochę lepszą wersję Screaming Frog.
Opis systemu
Podstawą systemu jest panel kontrolny gdzie wyświetlają się wszystkie domeny oraz wybrane parametry takie jak site wg. google. bing, Page Speed od Google, czasy odpowiedzi stosunek kodu do treści, robotsy, wszystkie nagłówki a także ile urli udało się przecrawlować, kiedy było ostatnie crawlowanie oraz w przypadku wykonywania crawlowania jaki nod je wykonuje. Tak wygląda system:
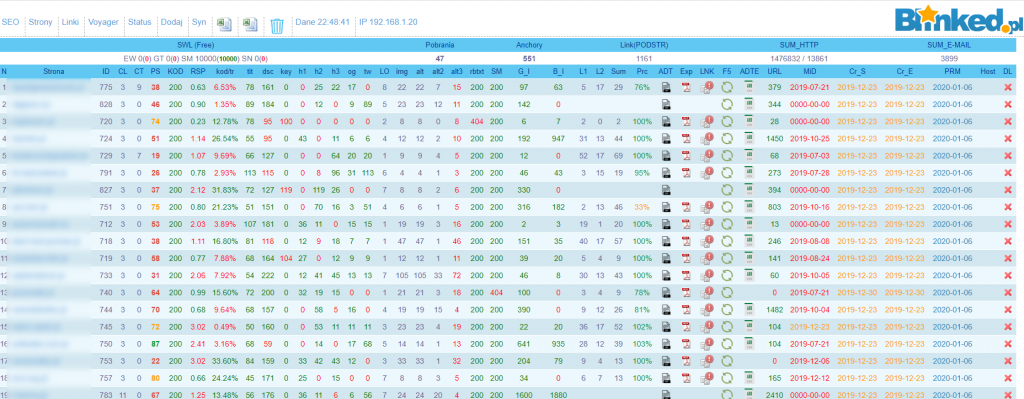
Nazwy pól po kolei co oznaczają:
- PS – Page Speed dla Destop w wersji 1 Page Speed Insights – może być podpięta każda wersja Page Speed – aktualna to chyba 5
- KOD – Nagłówek HTTP
- RSP – czas odpowiedzi do pobrania samego kodu HTML
- kod/tr – Stosunek treści do kodu – tutaj obliczam to podobnie jak SEO QUAKE ale czasami różnice w interpretacji kodu mogą być dość spore bo nie uwzględniam białych znaków
- tit – długość tytułu strony
- dsc – długość meta description
- key – długość meta keywords
- h1 – długość nagłówka h1
- h2 – długość nagłówka h2
- h3 – długość nagłówka h3
- og – OpenGraph – długość Open Graph
- tw – długość Twitter Cards
- LO – linki wychodzące
- img – liczba obrazków na stronie
- alt – liczba obrazów ze znacznikiem alt
- alt2 – liczba obrazów z prawidłowym (niepustym) znacznikiem alt
- alt3 – liczba obrazów dla których brakuje alt lub jest on pusty alt=””
- rbtxt – robots.txt czy dostępne
- SM – czy dostępna sitemapa
- G_I – google indeks – liczba podstron w indeksie google
- B_I – bing indeks – liczba podstron w indeksie bing
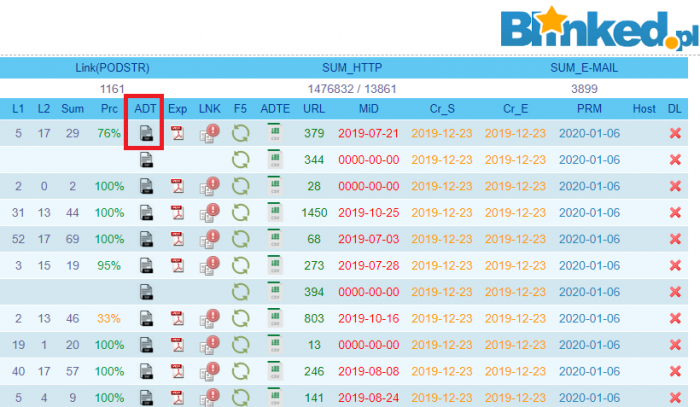
- L1 L2 Sum Prc – tutaj parametry jeżeli chodzi o linki
- ADT – gotowy audyt do pobrania
- Exp – export czystego pliku z wszystkimi danymi dla wszystkich URLi
- LNK F5 ADTE – odświeżenie + export gotowego audytu
- URL – Liczba przecrawlowanych URLi
- Cr_S Cr_E – kiedy rozpoczęło się crawlowanie i kiedy zakończyło
- Host – jaki host w danym momencie crawluje stronę
Oczywiście ten panel nie jest tylko frontem ale odpowiada za rozdzielenie zadań na nody (aby w tym samym czasie nie crawlowały tych samych stron itp) oraz pokazanie okrojonych do minimum parametrów stron – tak to co wypisałem to tylko część parametrów i to wyrażone w liczbach żeby się zmieściło 🙂
Parametry w panelu pobierane są dla danej witryny co 15 minut i jeżeli pojawi się coś niepokojącego jak np: noindex, nofollow w meta robots to wysyłany jest alert na maila. Nie da się ukryć że taki odpowiednik SEO Nagiosa czy Zabbixxa jest tym co świetnie pozwala się nie pogubić w gąszczu powyżej 100 domen, kiedyś kiedy świadczyłem usługi dla agencji dawał radę przy około 1500 domen.Dodatkowo codziennie robiony jest screen strony:
pobierane robots,txt:
tak aby w razie problemów widzieć co danego dnia się wydarzyło.
Sam crawler jest dość nieskomplikowany to skrypt PHP ostatnio w wersji 7.3 który łączy się z panelem i sprawdza czy dostępne jest zadanie do crawlowania i jedzie z koksem. W przypadku zawieszenia procesu sprawdza czy wcześniej się coś się nie zakończyło i rozpoczyna w miejscu przerwania – takie zabezpieczenie powoduje że w razie zawieszenia crawlowania (co zdarza się przy witrynach powyżej 1mln url) to crawlujemy od miejsca zawieszenia. Oczywiście robi się to całkowicie automatycznie więc jak coś wydarzy się w nocy to po 25 minutach proces jest automatycznie przywracany.
Crawler przechodzi przez wszystkie podstrony które są dostępne i poza banałami takimi jak wszystkie meta, canonicale sprawdza łacznie 40 parametrów między innymi stosunek kodu do treści, czasy odpowiedzi, czasy pobierania, objętości html, linki wewnętrzne, linki wychodzące itp. Co jest olbrzymią zaletą – potrzebuje pobrać jakieś specyficzne rzeczy na stronie – choćby sparsować ceny itp dodanie tego to chwila moment.
Skalowalność crawlera
Ponieważ crawler działa w oparciu o mój mały cluster proxmox oraz w nocy także o klaster beowulf ogranicza mnie tylko liczba stron do parsowania oraz przepustowość łącza.
Tak wygląda przenośny lab na którym siedzi sobie crawler:

Jeden nod w jednym czasie przy 2 GB RAMu i jednym core procesora 2Ghz ze spokojem może wykonywać po 10 requestów na sekunde – jest to niestety zabójstwo dla większości stron szczególnie że zabezpieczenie przed nadmiernym crawlowaniem posiada bardzo niewiele stron, Limitu URLi jako takiego nie ma ja dojechałem do 2 MLN adresów i strona się skończyła 🙂
W momencie w którym potrzebuje zwiększyć liczbę jednocześnie crawlowanych stron dokładam kolejnego noda i kolejnego i kolejnego. Przetestowałem 8 nodów na raz i baza była mocno dociążona ale cały system dawał radę. Dalsze skalowanie polega na dokładaniu parametrów do nodów i do samej bazy.
Tutaj screen jak to wygląda od strony klastra proxmox:

3 mysql i dwa spidery nody do crawlowania, dodanie kolejnego to po prostu zduplikowanie już istniejącego i nadanie mu nowej nazwy i tyle. W ten sposób można dodać ze spokojem 50 nodów.
W najlepszym teście udawało się wysyłać około 200 requestów na sekundę co już trochę ocierało się o DDoS i telefon z jednej z firm z informacją o olbrzymim obciążeniu ich infrastruktury. Możemy ze spokojem dojść do przepustowości wyszukiwarek takich jak google sprzed 15 lat 🙂
Eksport danych z crawlera
Dane pobrane z crawlera muszę jakoś wykorzystać dlatego dla każdej z domen można pobrać URLe wg,. wzorców czy to za długie title, podstrony ze zbyt dużą liczbą linków wychodzących – wszystkie zestawienia można pobrać dla każdej strony w formacie xlsx
Wszystko widać na screenie – tutaj oczywiście sorry za nazewnictwo ale jest to alpha do wewnętrznego użytku.

Jak widać mam zdefinowane jakieś rzeczy które muszę wyciągnąć dla danej domeny:
Jak widać na załączonym screenie dla każdej z domen mogę sobie wyeksportować w każdej chwili następujące dane:
- lista wszystkich przekierowań 301 w kodzie
- lista wszystkich podstron 404
- Lista podstron ze pustymi meta description
- lista wszystkich zduplikowanych tytułów podstron
- Brak altów lub błędne alty
- Podstrony z wypełnionym meta keywords
- Podstrony z pustym nagłówkiem H1
- Zdplikowane nagłówki H1
- Podstrony z pustym nagłówkiem H2
- Zdplikowane nagłówki H2
- Podstrony z pustym meta OPEN GRAPH
- Podstrony ze zduplikowanym meta Open Graph
- Meta robots które nie są puste
- Podstrony na których liczba linków wewnętrznych jest większa niż 100
- Podstrony na których liczba linków wychodzacych jest większa niż 10
- Podstrony ze stosunkiem kodu do treści poniżej 15%
- Podstrony z czasem odpowiedzi powyżej 1 sekundy
- Podstrony inne niż text/html
Tych definicji jest znacznie więcej i raczej tutaj ograniczeniem co chciałbym z czym porównać jest tylko i wyłącznie moja wyobraźnia.
Dane z każdego wiersza można wyeksportować do pliku Excel (.xls) lub CSV
Webiste/SEO Auditor
I przechodzimy do najważniejszej części czyli SEO Auditora. Jest to najnowsze dzieło i nie jest dokończone tylko dlatego że jest dużo pisania ale nie kodu a części opisowej a humanistą wybitnym nie jestem.
Po kliknięciu w panelu w ikonę:
Otrzymujemy taki normalny pisany audyt SEO:
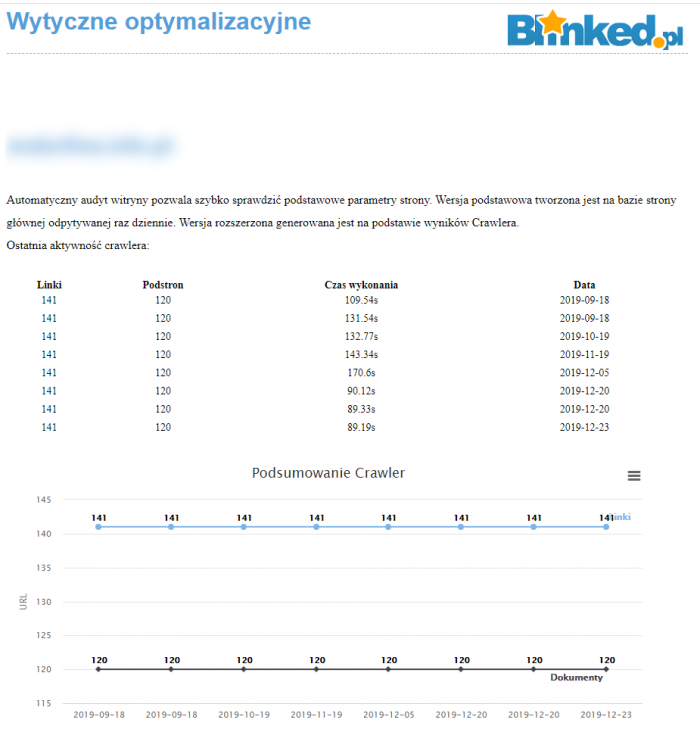
Liczba danych do przetworzenia jest olbrzymia więc kodowanie takiego audytu trwa i trwa jednak otrzymujemy praktycznie gotowy audyt z wytycznymi do wprowadzenia gdy rozpoczynamy współpracę z klientem. Oczywiście nie zastąpi to audytu wykonanego ręcznie i bardzo szczegółowo jednak pozwoli wyeliminować już na starcie bardzo wiele baboli i zaoszczędzi nam pisania ciągle tych samych wytycznych dla kolejnych stron.
Tak jak wspomniałem wcześniej audyt to od 10-30 stron wytycznych optymalizacyjnych z pogranicza SEO i infrastruktury:
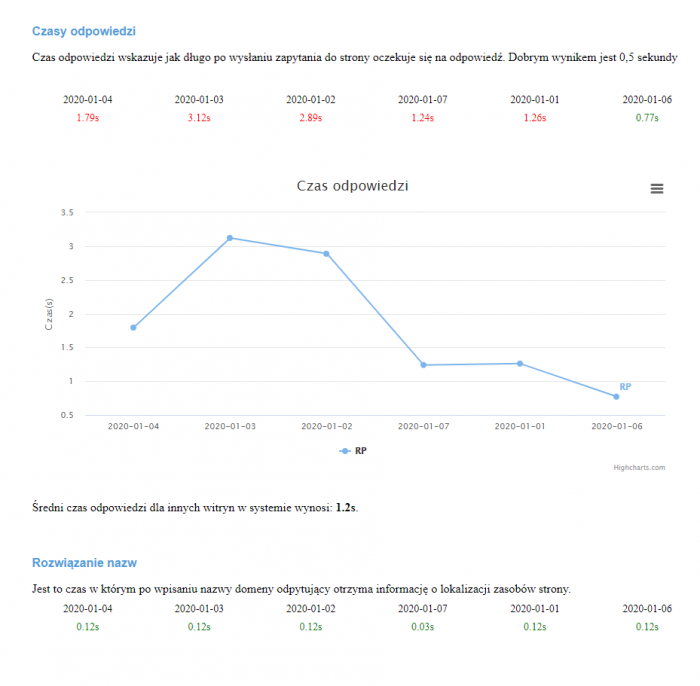 Na powyższym screenie widzimy jak wyglądają czasy odpowiedzi dla audytowanej domeny także w porównaniu do innych domen. Ogólnie parametrów typowo infrastrukturalnych jest 7.
Na powyższym screenie widzimy jak wyglądają czasy odpowiedzi dla audytowanej domeny także w porównaniu do innych domen. Ogólnie parametrów typowo infrastrukturalnych jest 7.
Kolejnym parametrem który jest sprawdzany a który często jest pomijany to otwarte podstawowe porty na serwerze czyli czy jest dostęp do MySQLa itp.:

Oczywiście są też sprawdzane codziennie parametry takie jak Page Speed:

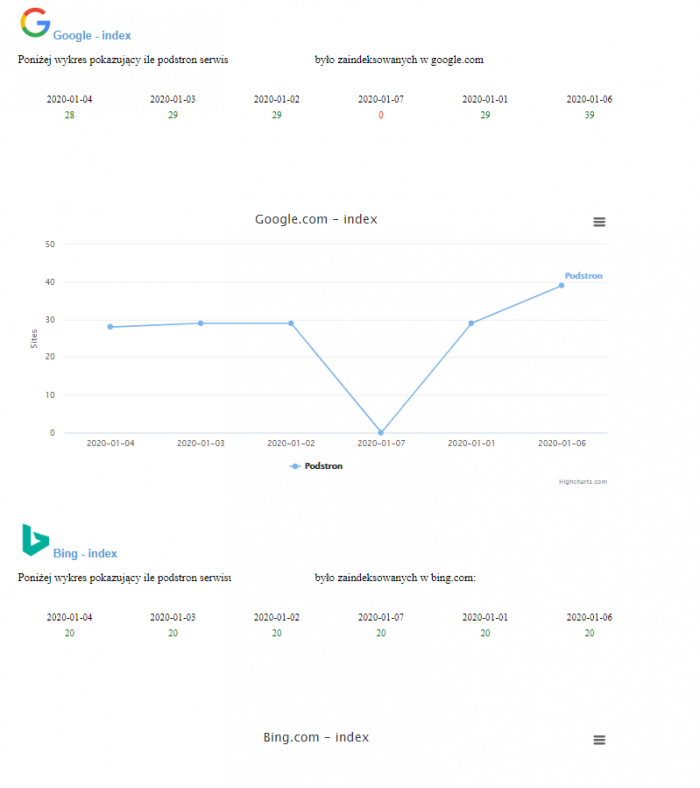
oraz poziom indeksacji w google oraz bing:
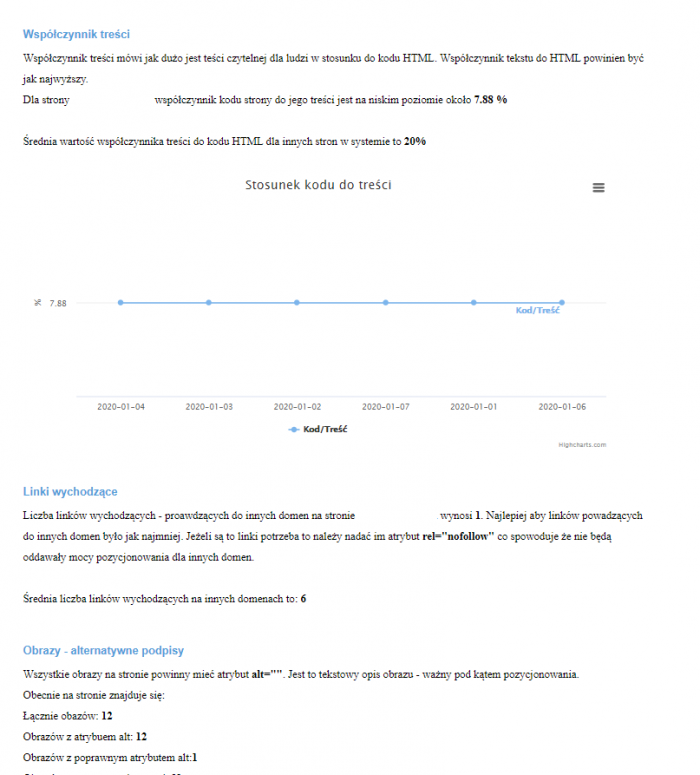
Wszystkie wcześniej wyeksportowane dane są pokazywane wraz z podpowiedziami co należałoby zmienić:
Nie prezentuje tutaj całości audytu bo wiadomo chciałbym to zostawić dla siebie ale niektórzy się przekonają jak duży audyt potrafi wyjść z tego narzędzia 🙂 Audyt jest dostępny w panelu by request oraz dodatkowo wysyłany raz w miesiącu na maila w postaci w miarę zgrabnego pliku .pdf
Inne funkcjonalności WEBSITE/SEO Auditor
Poza tym co pokazałem sam panel jest dużo bardziej rozbudowanym narzędziem – funkcji jest cała masa a to co wcześniej prezentowałem to tylko mały urywek:
- SWL – system do publikowania linków na zapleczach, statyczny, podobny do statlink czy do seomatik
- Voyager – system do przeszukiwania internetu działający pewnie podobnie do Brand24 jednak buduje tu konkurencje dla Google Bing – jestem tego pewien że w ciągu roku przeczesze dużą część internetu i stworze własną wyszukiwarkę – opisze to w następnym artykule
- Zarządzenie zapleczami SEO – sprawdzanie parametrów zaplecz, pobieranie statystyk z Piwik/Matomo, możliwość zdalnej publikacji treści, umieszczania linków itp
Podsumowanie
Na pewno mój system jeżeli chodzi o wydajność jest szybszy od Screaming Frog, ma też znacznie więcej możliwości, posiada bardzo podobne funkcjonalności do SEO Power Suite (z wyłączeniem sprawdzania linków) jednak lepiej sprawdzi się przy jednoczesnym parsowaniu wielu stron stron. Jest to bardzo duża automatyzacja audytów SEO bo w zasadzie po wrzuceniu adresu URL strony można już o wszystkim zapomnieć. System przecrawluje domenę, będzie sprawdzał codziennie dostępność serwisu, wszystkie parametry które są potrzebne, raz w miesiącu wyśle kompletny audyt, jak się coś wysypie to wyśle do mnie czy do webmastera strony mail z informacją że jest awaria, także z powodzenie zastąpi też Nagiosa w monitoringu infrastruktury (oczywiście w ograniczonym stopniu)
Co dalej?
Mały spojler – w Święta od pomysłów głowa mi pękała więc napisałem „parser internetu” który nazwałem voyager – przejechałem już ponad 1,5mln domen i cały czas ich przybywa i teraz piszę coś w stylu Brand24 czyli monitoring internetu (Michał Sadowski – spokojnie tylko do własnych potrzeb) a docelowo planuje parsować internet jak Google czy Bing i całkiem mi to nieźle idzie mimo że wykorzystuje do tego celu mój klaster Beowulf składający się z samych Pentium 4. Google też tak zaczynało więc pewnie już czują oddech mojego superkomputera na swoich plecach 🙂 Bójcie się tego potwora:

Podsumowanie podstawowych funkcjonalności panelu
Co daje panel SEO
W krótkich żołnierskich słowach główne korzyści które daje nasz panel:
1. 24 godzinny monitoring dostępności strony internetowej
2. Sprawdzanie ponad 40 parametrów strony głownej codzinnie
3. Comiesieczny audyt SEO wynikający z parsowania wszystkich podstron witryny
4. Codzienny zrzut wizualny strony www
5. Codzienne kopie ważnych elementów strony
6. Tygodniowe zestawienie dostępności strony w przypadku pojawiły się problem z odpowiedzią strony
7. Podstawowe wytyczne optymalizacje dla strony
8. Sprawdzanie zaindeksowania w google, bing
9. Automatyczne linkowanie w przypadku podpiecia stron satelit10. Sprawdzanie parametrów wydajnościowych Page Speed itp
10. Sprawdzanie parametrów wydajnościowych Page Speed itp

Mam nadzieje że to darmowe narzędzie ?:) Lepsze niż scream?
Narzędzie nie jest darmowe – ciężko oczekiwać żebym dwa lata pracy oddał komuś na za darmo. Czy lepsze niż scream? Inne bo to nie natywna aplikacja a serwerowa, bezobsługowa, działająca cyklicznie i praktycznie bez ograniczenia liczby stron mogących znajdować się w systemie.
Miło było przeczytać ten artykuł, że takie głowy są w naszym kraju. Łukasz napisał, że ma nadzieję, że darmowe będzie. Hmm. To takie typowe dla nas Polaków, za darmo, super support i jeszcze buzi dać. Michał powodzenia softem.
Bardzo dziękuje za miłe słowa i za tak zdroworozsądkowe podejście! Cały czas pracuje nad softem dalej ale to taka niekończąca się opowieść, co zrobię jedno to następne poprawiam i tak w kółko
I to lubię. Kreatywne podejście do marketingu. Fajne alternatywa, ale screaming frog ma naprawdę solidną infrastrukturę oraz zaplecze. Ciężko będzie ich wygryźć.
Tutaj raczej infrastruktura ani zaplecze nie mają takeigo znaczenia bo mój soft robi to samo ale w inny sposób. ScreamingFrog crawluje tak szybko jak pozwala mu maszyna na której jest postawiony. Moje oprogramowanie jest skalowalne i na jednej fizycznie maszynie może parsować w jednym czasie kilkanaście stron bez ingerencji użytkownika. Dziękuje za miły komentarz
Gratuluję kreatywnego podejścia do tematu! Stworzyłeś świetną alternatywę dla ScreamingFrog – przedstawione możliwości softu o tym świadczą. Dzięki Tobie mamy jedną opcję więcej do wyboru z obecnie dostępnych na rynku.